
Abstract. 3D models provide a common ground for different representations of human bodies. In turn, robust 2D estimation has proven to be a powerful tool to obtain 3D fits “in-the- wild”. However, depending on the level of detail, it can be hard to impossible to acquire labeled data for training 2D estimators on large scale. We propose a hybrid approach to this problem: with an extended version of the recently introduced SMPLify method, we obtain high quality 3D body model fits for multiple human pose datasets. Human annotators solely sort good and bad fits. This procedure leads to an initial dataset, UP-3D, with rich annotations. With a comprehensive set of experiments, we show how this data can be used to train discriminative models that produce results with an unprecedented level of detail: our models predict 31 segments and 91 landmark locations on the body. Using the 91 landmark pose estimator, we present state-of-the art results for 3D human pose and shape estimation using an order of magnitude less training data and without assumptions about gender or pose in the fitting procedure. We show that UP-3D can be enhanced with these improved fits to grow in quantity and quality, which makes the system deployable on large scale. The data, code and models are available for research purposes.








Bibtex:
@inproceedings{Lassner:UP:2017,
title = {Unite the People: Closing the Loop Between 3D and 2D Human Representations},
author = {Lassner, Christoph and Romero, Javier and Kiefel, Martin and Bogo, Federica and Black, Michael J. and Gehler, Peter V.},
booktitle = {IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
month = jul,
year = {2017},
url = {http://up.is.tuebingen.mpg.de},
month_numeric = {7}
}
The images for the datasets originate from the Leeds Sports Pose dataset and its extended version, as well as the single person tagged people from the MPII Human Pose Dataset. Because we publish several types of annotations for the same images, a clear nomenclature is important: we name the datasets with the prefix “UP” (for Unite the People, optionally with an “i” for initial, i.e., not including the FashionPose dataset). Followed by a dash, we specify the type of the annotation (Segmentation, Pose or 3D) and the granularity. If the annotations have been acquired by humans, we append an “h”. We make the annotations freely available for academic and non-commercial use (see also license). For the images always the license of the original dataset applies, we only provide our cut-outs for convenience and reproducibility. The datasets are linked from their respective thumbnail image. For each image in UP-3D, we also provide a file with quality information ('medium' or 'high') of the 3D fits. 'medium' means that the rough areas of the body are overlapping with the image evidence. Rotation of the limbs is not necessarily correct. A 'high' rating indicates that limb rotation is also mostly correct. For the pose datasets, we only use images with the 'high' rating.


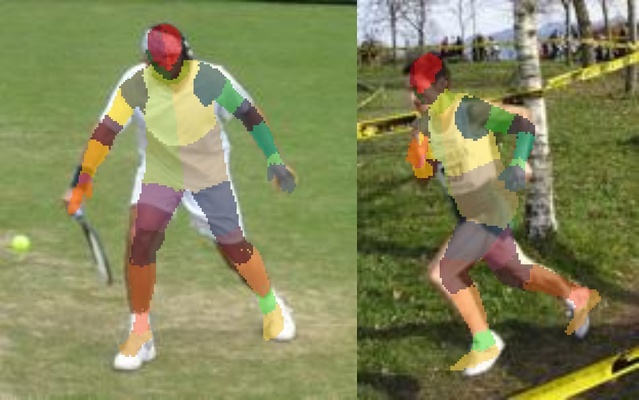

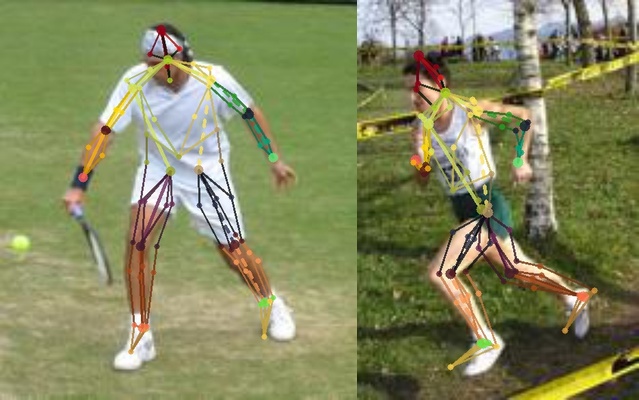
Our six body part segmentation annotations from human annotators for evaluation on the Leeds Sports Pose Dataset is included in the UPi-S1h download.
To setup the various datasets for use with the code:
- Unzip UP-3D to the UP3D_FP folder configured in config.py.
- Unzip UP-S31 into the folder `SEG_DATA_FP/31/500/pkg_dorder` with SEG_DATA_FP as configured in config.py. `pkg_dorder` is the dataset name that must be used during training. There are four .txt files included in the extracted folder. These must be moved into the folder [up install path]/segmentation/training/list/. Then you can for example run in the segmentation folder: `run.sh trfull segmentation pkg_dorder`.
- Unzip UP-P14/P91 into the folder `POSE_DATA_FP/{14,91}/500/p{14,91}_joints` with POSE_DATA_FP as configure in config.py. There are again list files in the unzipped folders that must be moved into the folder [up install path]/pose/training/list/. The dataset names are `p{14,91}_joints`; you can for example run in the pose folder `run.sh trfull pose p91_joints`.
We provide our trained models for download. They are freely available for academic and non-commercial use (see also license). Click the thumbnails for downloading (the direct prediction model will be made available together with the code). The `S31' model must be run with the Deeplab V2 caffe, the `P91' model was trained with the Deepercut-CNN caffe, but should run for deployment with any recent caffe version.


Unzip s31.zip to [up install path]/segmentation/training/model/segmentation/ and s91.zip to [up install path]/pose/training/model/pose/.
You can find our code including the training scripts on github. The code for fitting 3D bodies to silhouettes is currently not included, solely due to a licensing problem with the CGAL library that we used for our implementation. The segmentation labeling tool can be found here.
We make the code as well as the datasets available for academic or non-commercial use under the Creative Commons Attribution-Noncommercial 4.0 International license.